 EdgeFlow
EdgeFlowDeploy LLM/VLM anywhere.
Run efficiently everywhere.
The compatibility layer for AI inference. Deploy LLMs and VLMs
across CPU, GPU, and edge—without rewriting a single line.

Built for production AI
Everything you need to ship models without infrastructure headaches.
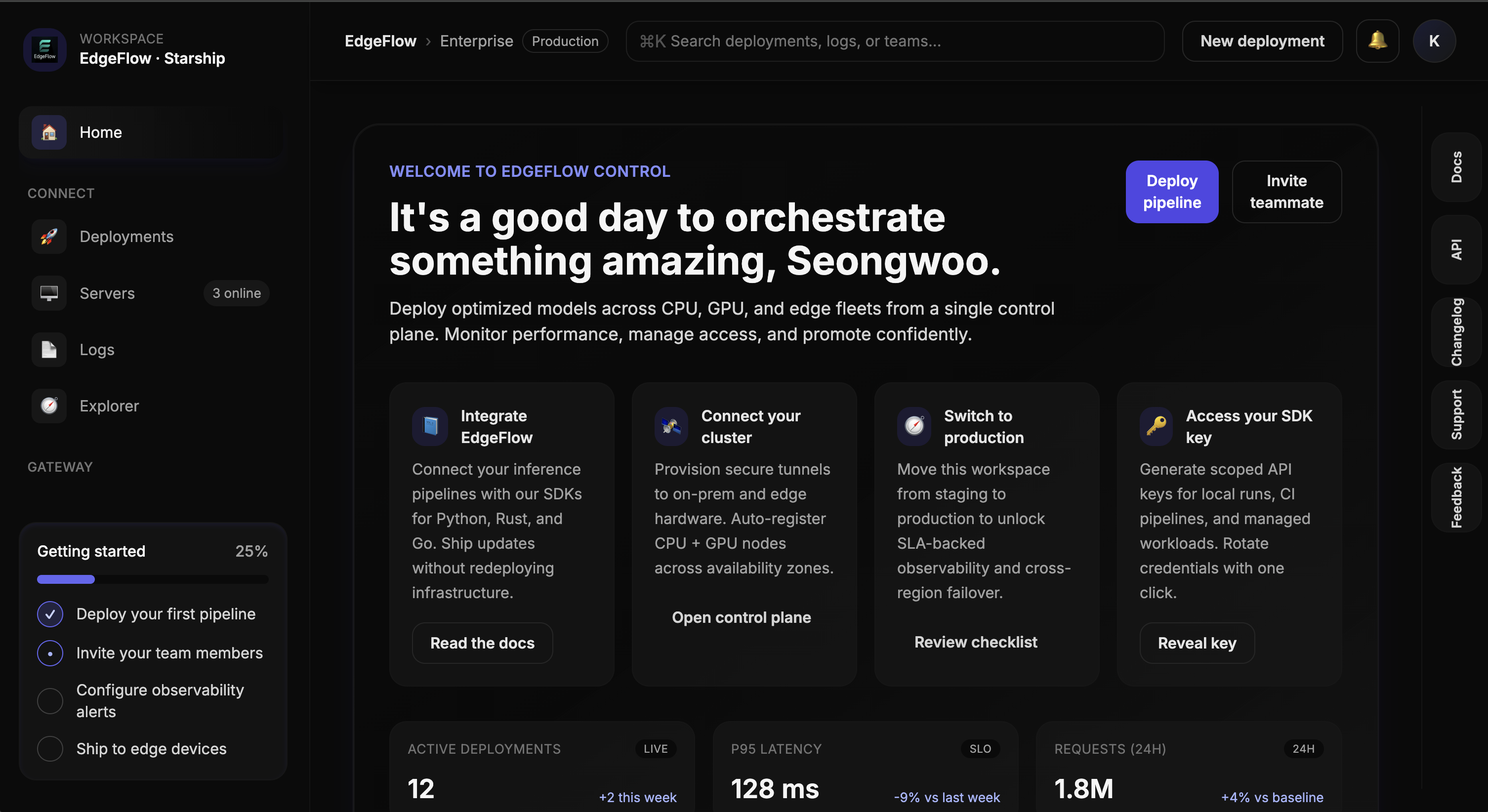
One console for every deployment
Track CPU and GPU workloads, manage access policies, and promote releases from staging to production without leaving the dashboard.
Close the loop on reliability
Streaming metrics, proactive SLO alerts, and guided runbooks help your operators resolve incidents before customers notice.
Security & compliance baked in
Audit trails, role-based controls, and SOC2-ready policies make it easy to bring EdgeFlow into regulated environments.
InferX
Core Inference Engine
Executes LLMs and VLMs efficiently across CPU, GPU, and edge hardware. Ensures optimal performance independent of environment.
ModelRun
Deployment & Management
Handles model packaging, integration, and rollout. Automates deployment pipelines for enterprises.
CoreShift
Dynamic Hardware Optimizer
Monitors and reallocates compute resources in real time. Cuts inference cost by 40% through efficient utilization.
Unified Stack
End-to-End Platform
Model Abstraction Layer, Compiler Optimization, Unified Runtime, and Monitoring & CI/CD Integration.
The EdgeFlow Stack
Three layers. One unified platform.
InferX — Universal Runtime Layer
Executes LLMs and VLMs efficiently across any hardware. Quantization and optimized CPU kernels deliver strong throughput without GPU dependency. Add acceleration when you need it.
from edgeflow import InferX
# Load model with CPU optimization
model = InferX.load("qwen-vl-3b", device="cpu")
# Generate with streaming
response = model.generate(
prompt="Analyze this chart",
image=image_data,
max_tokens=512,
stream=True
)
for chunk in response:
print(chunk, end="")CoreShift — Dynamic Hardware Balancer
Monitors and reallocates compute resources in real time. Balances load across CPUs, GPUs, and edge nodes automatically. Cuts inference cost by 40% through efficient utilization.
ModelRun — Ship Models, Not YAML
Package. Deploy. Rollback. Automated pipelines for ML teams. Staging-to-production workflows that adapt to your infrastructure.
Package your model into an EdgeFlow bundle.
Expose REST and streaming endpoints.
Ship to edge or cloud with your CI pipeline.
Track latency and cost with built-in metrics.
Why engineering teams choose EdgeFlow
Keep Data On-Prem
Deploy at the edge or in your own data center. Full control over sensitive workloads. Air-gapped options available.
One Runtime, Everywhere
LLM and VLM on the same interface. Laptop, cloud, or edge—no code changes. Same APIs, same behavior.
Quantized Performance
Optimized kernels and quantization deliver GPU-class throughput on CPU infrastructure. No expensive hardware required.
{
"model": "edgeflow-qwen-3-vl",
"input": {
"prompt": "Summarize this image",
"image": "data:image/png;base64,..."
},
"params": {
"max_tokens": 2048,
"temperature": 0.2
}
}curl -X POST \
https://api.edgeflow.local/v1/generate \
-H "Authorization: Bearer <token>" \
-d @request.jsonKey Features
Everything you need to deploy AI models efficiently at scale.
CPU-first inference
Run LLM and VLM on any hardware with low memory footprint and strong throughput. Our optimized kernels and quantization techniques deliver production-grade performance without requiring expensive GPUs.
Consistent deploys
One runtime across laptop, data center, and edge. Same APIs, same behavior.
Lower TCO
Reduce GPU spend using CPU pools without loss of quality for many workloads.
Enterprise ready
FastAPI endpoints, auth, observability, and CI/CD hooks built in. Deploy with confidence using battle-tested infrastructure.
Simple pricing. Scale as you grow.
Start free, upgrade when you need more power.
Forever free
- Local development
- Single model
- Community support
/month, billed monthly
- CPU clusters
- REST and streaming
- Metrics and dashboards
- Email support
For your scale
- SLA and SSO
- Air-gapped deploy
- On-site support
- Custom integrations
Frequently Asked Questions
Find answers to common questions about EdgeFlow
Do I need GPUs?
No. EdgeFlow targets CPUs first. You add GPUs later if needed for additional performance.
Which models are supported?
LLM and VLM families with quantization support: Qwen-VL, Gemma, Llama, and more.
Can I deploy on-prem?
Yes. Air-gapped options available for enterprise customers.
What's the typical TCO reduction?
CoreShift reduces infrastructure costs by 40% through efficient CPU utilization.
Is EdgeFlow open source?
Yes. Core components are MIT-licensed. Commercial and usage-based options also available.
Ready to deploy AI anywhere?
Join teams running production inference without GPU lock-in.